I modelli di deep learning che generano immagini a partire da una descrizione testuale sono diventati sempre più popolari, ma spesso sono disponibili solo online e a pagamento. In questo articolo, ti spiegheremo come installare e utilizzare gratuitamente Stable Diffusion sul tuo PC, permettendoti di creare immagini con l’intelligenza artificiale comodamente da casa.

Le applicazioni che permettono di generare immagini a partire da una descrizione testuale, conosciute come “IA generative”, hanno catturato l’attenzione del pubblico, soprattutto grazie ai recenti sviluppi nel campo dei chatbot come ChatGPT e del sistema di ricerca Bing. Tra le più note si trovano DALL-E 2 di OpenAI, Midjourney dal laboratorio di ricerca omonimo e Stable Diffusion, creata dal gruppo di ricerca CompVis dell’Università Ludwig Maximilian di Monaco con il supporto finanziario di Stability AI.
È importante notare che questi sistemi vengono spesso definiti “IA” per semplificazione comunicativa. Il termine “Intelligenza Artificiale” è ampio e comprende diverse applicazioni, ed è conosciuto fin dagli anni ’50. All’interno di questo campo, ci sono diversi tipi di intelligenza artificiale che superano le capacità umane in specifici compiti e vengono comunemente chiamate “Narrow AI” o “Intelligenze Artificiali Strette”.
Le “Narrow AI” sono il risultato di sistemi di machine learning che possono fare uso di reti di deep learning. Pertanto, l’intelligenza artificiale può essere vista come una sorta di matrioska: l’IA contiene il machine learning, che a sua volta contiene il deep learning. È importante comprendere questa distinzione per apprezzare il contesto e l’applicazione di Stable Diffusion nel creare immagini con l’IA sul tuo PC.
Il Machine Learning, o Apprendimento Automatico, rappresenta un sottoinsieme dell’Intelligenza Artificiale ed è basato su un sistema di algoritmi che possono identificare schemi all’interno dei dati e svolgere compiti senza necessitare di istruzioni esplicite. Invece, si basa su modelli e inferenze per prendere decisioni.
Il Deep Learning, a sua volta, è un sottoinsieme del Machine Learning. Gli algoritmi di Deep Learning sono stati sviluppati per migliorare l’efficienza delle tecniche tradizionali di Machine Learning, chiamate “supervisionate”, che richiedono un intervento umano per addestrare il software. Ad esempio, assegnare un’etichetta testuale a un’immagine, far elaborare tali immagini agli algoritmi, testare gli algoritmi su immagini sconosciute, verificare i risultati e migliorare il set di dati etichettando nuove immagini.
Mentre il Machine Learning richiede una pre-elaborazione dei dati, il Deep Learning si avvale di reti neurali artificiali, ispirate al funzionamento del cervello umano, capaci di individuare schemi in dati non strutturati e non pre-elaborati. Ad esempio, se si dispone di un insieme di foto di diversi animali da categorizzare, come “gatto”, “cane”, “topo”, gli algoritmi di Deep Learning sono in grado di determinare quali caratteristiche sono più rilevanti per distinguere un animale dall’altro. Potrebbero, ad esempio, comprendere che le orecchie di questi tre animali sono un elemento distintivo significativo per completare la categorizzazione.

Ora, concentrandoci sulla creazione di immagini a partire da rumore, entriamo nel contesto della “diffusione latente”. DALL-E 2, Midjourney e Stable Diffusion, più che rappresentare l’Intelligenza Artificiale in senso stretto, sono modelli di Deep Learning capaci di generare immagini interpretando una descrizione testuale, comunemente definita “prompt”.
Questi modelli si basano su un tipo di modello generativo chiamato “diffusione latente” (Latent Diffusion), anche se con differenze specifiche per ciascuno di essi. Semplificando il processo, un modello di diffusione prende le immagini di addestramento e le “distrugge” aggiungendo del “rumore” gaussiano. Attraverso questo addestramento, il modello impara a recuperare i dati invertendo il processo e rimuovendo il rumore per ottenere un’immagine finale.
In pratica, un modello di diffusione è in grado di generare immagini partendo da un rumore simile a un’immagine che ha imparato a riconoscere. Durante ogni passaggio del processo di costruzione dell’immagine (chiamati “step”), il rumore viene gradualmente ridotto fino ad ottenere il risultato finale.Free Research Preview.
La caratteristica distintiva di un modello di diffusione latente risiede nel fatto che lavora nello spazio latente dell’immagine anziché nel dominio dei pixel reali dell’immagine stessa. Questo approccio permette di ottenere risultati in modo più efficiente, richiedendo meno tempo e meno calcoli.
Tuttavia, avere questa capacità da sola non è sufficiente per creare un’immagine a partire da una descrizione. Il modello deve anche essere in grado di “comprendere” il testo fornito dall’utente per descrivere l’immagine desiderata. Per fare ciò, viene utilizzato un encoder che elabora il testo in input e produce una serie di vettori che rappresentano ciascuna parola e che possono essere riconosciuti dal generatore di immagini.
L’encoder traduce il testo in una forma che il generatore di immagini può comprendere, consentendo una comunicazione efficace tra la descrizione testuale e il processo di generazione dell’immagine. In questo modo, il modello può utilizzare l’informazione testuale per guidare la generazione delle immagini desiderate.
Questo approccio combinato di utilizzo dello spazio latente dell’immagine e dell’elaborazione del testo tramite un encoder consente al modello di diffusione latente di creare immagini realistiche e coerenti a partire da una descrizione testuale. La capacità di interpretare il testo e generare immagini coerenti rappresenta un notevole progresso nell’ambito dell’Intelligenza Artificiale e offre nuove opportunità per la creazione di contenuti visivi creativi e innovativi.

La forza distintiva di un modello di diffusione latente risiede nel suo approccio di lavoro nello spazio latente dell’immagine anziché nel dominio dei pixel reali, il che porta a un notevole risparmio di tempo e risorse computazionali. Lo spazio latente rappresenta una “versione compressa” dell’immagine, che contiene le informazioni essenziali per la sua generazione.
Tuttavia, la capacità di lavorare nello spazio latente da sola non è sufficiente per creare un’immagine a partire da una descrizione. Il modello deve anche essere in grado di “capire” il testo fornito dall’utente per descrivere l’immagine desiderata. Per raggiungere questo obiettivo, viene utilizzato un encoder che elabora il testo in input e produce un elenco di vettori che rappresentano ciascuna parola.
I vettori prodotti dall’encoder sono progettati in modo tale da poter essere riconosciuti e utilizzati dal generatore di immagini. Questo permette al modello di comprendere il significato delle parole all’interno della descrizione testuale e di tradurlo in un’elaborazione visiva coerente.
L’utilizzo dell’encoder consente una comunicazione efficace tra il testo descrittivo e il processo di generazione dell’immagine. Il modello di diffusione latente può quindi sfruttare l’informazione testuale per guidare il processo di generazione delle immagini desiderate.
Attraverso l’integrazione dello spazio latente, l’encoder e il generatore di immagini, il modello di diffusione latente riesce a creare immagini realistiche e coerenti a partire da una descrizione testuale. Questo approccio avanzato nell’ambito dell’Intelligenza Artificiale apre nuove prospettive per la generazione di contenuti visivi creativi e innovativi.

Nonostante il processo complesso di machine learning che abbiamo appena introdotto, la possibilità di generare immagini a partire da descrizioni testuali è resa accessibile grazie all’esistenza di applicazioni mobili, web o fruibili tramite la piattaforma social Discord. Queste applicazioni offrono interfacce utente più o meno semplici per consentire agli utenti di creare le immagini desiderate.
Tuttavia, la maggior parte di questi servizi richiede un pagamento per l’utilizzo, ad eccezione di un numero limitato di token iniziali che vengono consumati ad ogni generazione. Una volta esauriti, gli utenti devono acquistare ulteriori token o sottoscrivere un abbonamento mensile per continuare a utilizzare il servizio.
Tra i vari modelli generativi disponibili, Stable Diffusion si distingue per essere open-source, il che significa che gli utenti hanno la possibilità di installare il software direttamente sui propri PC e generare immagini in modo autonomo, senza limitazioni di utilizzo o costi aggiuntivi. Sebbene i requisiti minimi non siano accessibili a tutti, non sono particolarmente restrittivi: è sufficiente disporre di un buon PC da gaming.
Questa caratteristica di accesso aperto e flessibilità rende Stable Diffusion un’opzione allettante per gli appassionati che desiderano creare immagini personalizzate in modo conveniente e senza dipendere da servizi a pagamento. L’installazione locale sul proprio PC consente di sfruttare appieno il potenziale del modello generativo, offrendo un’esperienza personalizzata e controllata direttamente dall’utente.
Utilizzare Stable Diffusion tramite un’interfaccia nel browser è il modo più conveniente per generare immagini sul proprio PC. Una delle opzioni più popolari è “Stable Diffusion WebUI”, creata dall’utente GitHub AUTOMATIC1111. Può essere installata tramite un processo manuale che richiede diversi passaggi oppure utilizzando un installer.
L’installer chiamato “A1111 WebUI Easy Installer and Launcher” è stato sviluppato dall’utente GitHub EmpireMediaScience. Pur non avendo un’affiliazione diretta con Stable Diffusion WebUI, funziona molto bene e semplifica notevolmente il processo di installazione, evitando la necessità di installare manualmente Python 3.10.6.
Sebbene Stable Diffusion WebUI sia compatibile anche con schede grafiche AMD e con Mac Apple Silicon, l’installer semplificato è stato testato solo con schede grafiche Nvidia.
Stable Diffusion fa affidamento sulla quantità di VRAM (memoria video) della scheda grafica. È consigliabile utilizzare almeno una scheda Nvidia della serie RTX 1000 con almeno 4 GB di VRAM, anche se è preferibile disporre di 8 GB. Naturalmente, più VRAM si ha a disposizione, migliore sarà la performance del sistema, consentendo di lavorare con immagini ad alta risoluzione e ottenere risultati più rapidi.
Lo spazio occupato sul disco per l’installazione è di circa 10 GB, ma sarà necessario aggiungere ulteriori spazio per i modelli safetensor o i LoRA che si desidera installare successivamente. Spiegheremo più avanti cosa sono questi modelli.
Abbiamo testato Stable Diffusion su un PC di prova abbastanza datato ma che ha comunque ottenuto buoni risultati. Il sistema comprende un processore i5-8600K overclockato a 4,8 GHz, 16 GB di RAM a 3200 MHz e una scheda grafica RTX 2060 Super con 8 GB di VRAM.
Per iniziare, è necessario scaricare l’ultima versione dell’eseguibile A1111 WebUI Easy Installer and Launcher e installarlo come amministratore. Una volta aperta la finestra di installazione, sarà possibile scegliere la cartella di destinazione sull’unità disco in cui verrà installata l’interfaccia grafica. Cliccando su “Install”, l’eseguibile avvierà il download delle componenti necessarie (Python 3.10.6 e Git for Windows) e della repository di Stable Diffusion WebUI.
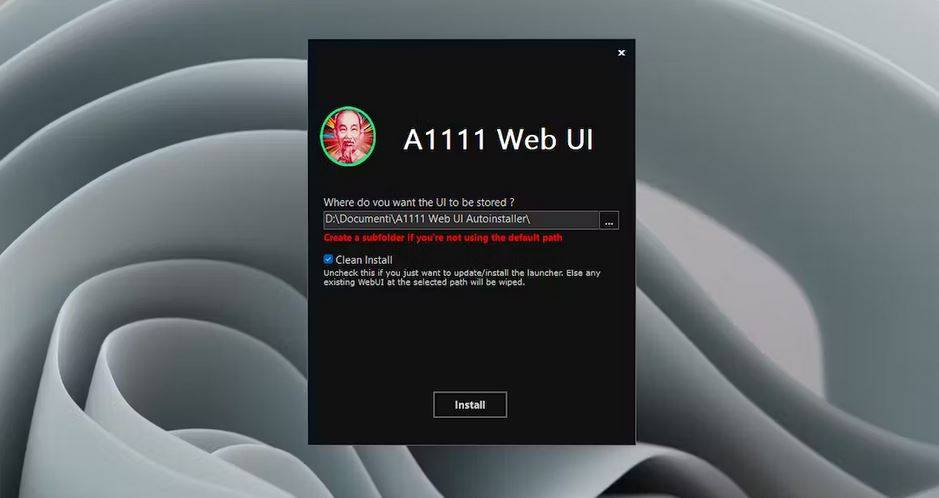
Se Python 3.10.6 non è già presente sul proprio PC, l’installer provvederà al suo download in modo automatico. Tuttavia, consigliamo comunque di effettuare l’installazione manuale di Python 3.10.6 prima di avviare l’installer, per garantire una corretta configurazione.
Il processo di installazione richiederà del tempo, che varierà anche in base alla velocità della connessione Internet. Una volta completato, nella cartella di destinazione scelta all’inizio dell’installazione comparirà un collegamento PowerShell chiamato “A1111 WebUI (Pin to Taskbar)”. È possibile cliccarci sopra per aprirlo, oppure trascinarlo sulla scrivania o sulla barra delle applicazioni per averlo sempre a portata di mano.
All’apertura del collegamento “A1111 WebUI (Pin to Taskbar)” per la prima volta, l’applicazione scaricherà e installerà le risorse rimanenti e chiederà se si desidera scaricare il modello di base di Stable Diffusion per generare immagini. È consigliabile scegliere “sì” per avere immediatamente un modello di partenza con cui iniziare a creare immagini.
Da quel momento in poi, per accedere all’interfaccia web e generare immagini con Stable Diffusion, sarà sufficiente fare doppio clic sul collegamento “A1111 WebUI (Pin to Taskbar)”, il quale aprirà il launcher.
Il launcher, rappresentato da una finestra verticale, consente di effettuare alcune scelte per le impostazioni.
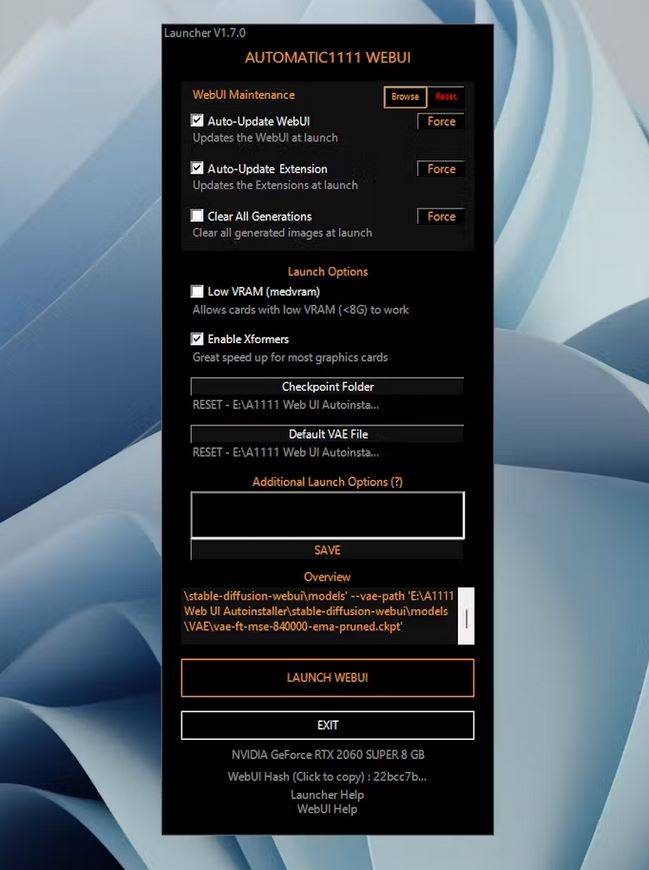
È importante prestare maggiore attenzione alla spunta “Low VRAM – Allow cards with low VRAM (<8 GB) to work” e attivarla solo se si possiede una scheda grafica con meno di 8 GB di VRAM. Nel caso della RTX 2060 Super con 8 GB di VRAM, questa opzione non è necessaria e può essere lasciata deselezionata.
Si consiglia di attivare “Auto-Update WebUI” per mantenere l’interfaccia utente sempre aggiornata, così come “Auto-Update Extensions”. È altamente consigliato anche attivare “Enable Xformers”.
Nella casella “Additional Launch Options” è possibile digitare “–no-half”. Questa opzione è consigliata per l’utilizzo dei modelli basati su Stable Diffusion 2.1 addestrati su immagini da 768 x 768 pixel, ma non è essenziale. In alcuni casi, potrebbe causare problemi di allocazione di memoria CUDA.
Una volta pronti, fare clic su “LAUNCH WEBUI” e attendere che la console di Windows, aperta in background, carichi l’interfaccia grafica, che sarà quindi visualizzata automaticamente nel browser all’indirizzo http://127.0.0.1:7860/.
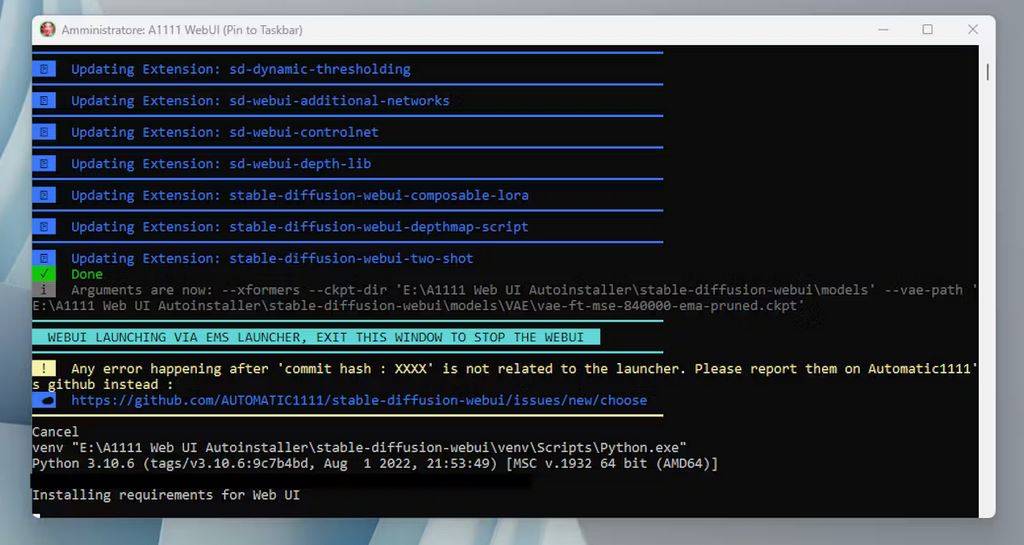
I modelli Stable Diffusion sono file associati all’algoritmo di generazione di immagini e sono fondamentali per il funzionamento di Stable Diffusion WebUI. Essi rappresentano la conoscenza appresa dal modello di diffusione latente durante il processo di addestramento.
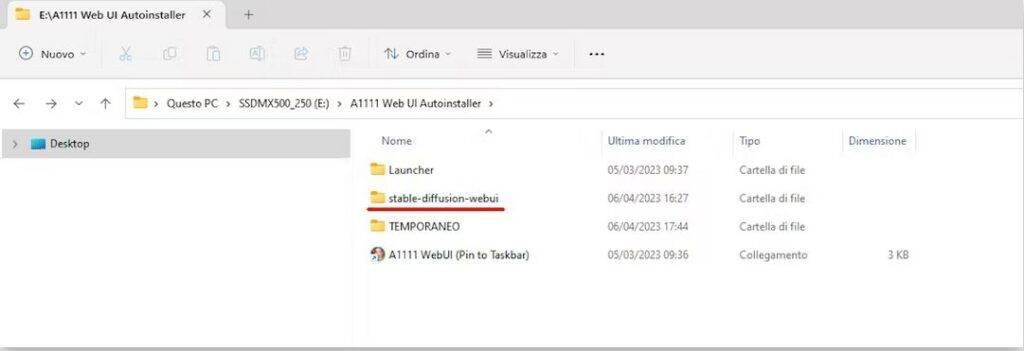
Nella directory di A1111 WebUI Autoinstaller, dopo l’installazione, è presente una cartella chiamata “\stable-diffusion-webui\models”. All’interno di questa cartella si trovano i modelli che possono essere utilizzati per generare le immagini. I modelli sono solitamente file con estensione “.pt” o “.pkl”.
Per utilizzare un modello specifico, è necessario copiarlo nella cartella corrispondente del percorso di installazione di Stable Diffusion WebUI. Solitamente, il percorso predefinito è “C:\StableDiffusionWebUI\stable-diffusion-webui\models”. Assicurarsi di copiare il file del modello nella cartella corretta per renderlo disponibile all’interno dell’interfaccia utente.
I modelli possono essere scaricati da fonti affidabili o possono essere addestrati autonomamente utilizzando gli strumenti e i dataset appropriati. È importante utilizzare modelli affidabili e di qualità per ottenere risultati ottimali durante la generazione di immagini con Stable Diffusion.
I modelli Stable Diffusion possono essere trovati su diversi siti, tra cui Hugging Face, lo spazio Discord di Stable Foundation e Civitai. Questi modelli sono generalmente chiamati “checkpoint” e sono associati all’estensione del file utilizzata per crearli, come ad esempio “.ckpt”. Tuttavia, più recentemente sono stati introdotti modelli con estensione “.safetensor”.
I file con estensione “.ckpt” rappresentano checkpoint del modello, che possono essere salvati durante il processo di addestramento per riprendere l’addestramento in un secondo momento o per utilizzare il modello addestrato per la generazione di immagini.
I file con estensione “.safetensor” sono una variante dei checkpoint, specifica per Stable Diffusion. Essi sono stati introdotti per garantire una maggiore sicurezza nel caricamento dei modelli e per evitare rischi legati a potenziali vulnerabilità. Questa nuova estensione è stata implementata per fornire una migliore protezione dei modelli e prevenire usi impropri o abusi.
È importante assicurarsi di scaricare modelli da fonti affidabili e verificarne l’autenticità. Prima di utilizzare un modello, è consigliabile leggere le istruzioni fornite con il modello stesso per comprendere i requisiti e le specifiche di utilizzo corrette.
È importante prestare attenzione e scaricare modelli da fonti affidabili per evitare potenziali rischi legati alla sicurezza dei file. Si consiglia di non scaricare file .ckpt da fonti non verificate, a meno che non siano forniti da Stability AI, i quali dovrebbero essere relativamente sicuri. È possibile trovarli sulla pagina di Stability AI su Hugging Face e includono modelli Stable Diffusion di base come la versione 1.5 e 2.1.
I modelli possono avere dimensioni variabili, mediamente comprese tra 2 GB e 4 GB, ma ci possono essere anche checkpoint più grandi, come ad esempio da 7 GB o 8 GB.
Alcuni modelli fanno uso di Variational Autoencoder (VAE), che sono strumenti importanti utilizzati dai modelli per facilitare la generazione dell’immagine a partire dal rumore nello spazio latente. Se necessario, è possibile copiare i file VAE specifici all’interno della cartella “A1111 Web UII Autoinstaller\stable-diffusion-webui\models\VAE”. Si consiglia di verificare le istruzioni specifiche fornite con il modello per determinare se è necessario copiare ulteriori file VAE e quali sono i nomi corretti da utilizzare.
Di solito, l’installer si occupa di copiare i file VAE nella cartella corretta, come ad esempio il file più recente “vae-ft-mse-840000-ema-pruned.ckpt”. Tuttavia, è sempre consigliabile verificare che il file sia stato correttamente copiato nella cartella “A1111 Web UII Autoinstaller\stable-diffusion-webui\models\VAE” e, se necessario, procedere manualmente alla sua copia.
Assicurarsi di seguire le istruzioni fornite con i modelli e con l’installer per garantire un corretto funzionamento e utilizzo dei modelli Stable Diffusion.

È fondamentale prestare attenzione e scaricare modelli da fonti affidabili al fine di evitare potenziali rischi per la sicurezza dei file. Si raccomanda di non scaricare file .ckpt da fonti non verificate, a meno che non siano forniti da Stability AI, i quali dovrebbero essere relativamente sicuri. È possibile trovarli sulla pagina di Stability AI su Hugging Face e includono modelli Stable Diffusion di base come la versione 1.5 e 2.1.
I modelli possono avere dimensioni variabili, in genere comprese tra 2 GB e 4 GB, ma è possibile trovare anche checkpoint più grandi, come ad esempio da 7 GB o 8 GB.
Alcuni modelli fanno uso di Variational Autoencoder (VAE), che rappresentano strumenti importanti utilizzati dai modelli per facilitare la generazione delle immagini a partire dal rumore nello spazio latente. Se necessario, è possibile copiare i file VAE specifici nella cartella “A1111 Web UII Autoinstaller\stable-diffusion-webui\models\VAE”. È consigliabile consultare le istruzioni specifiche fornite con il modello per determinare se è necessario copiare ulteriori file VAE e quali sono i nomi corretti da utilizzare.
Di solito, l’installer si occupa di copiare i file VAE nella cartella corretta, come ad esempio il file più recente “vae-ft-mse-840000-ema-pruned.ckpt”. Tuttavia, è sempre consigliabile verificare che il file sia stato correttamente copiato nella cartella “A1111 Web UII Autoinstaller\stable-diffusion-webui\models\VAE” e, se necessario, procedere manualmente alla sua copia.
Assicurarsi di seguire attentamente le istruzioni fornite con i modelli e con l’installer al fine di garantire un corretto funzionamento e utilizzo dei modelli Stable Diffusion.
Inoltre, è importante notare che i modelli basati su Stable Diffusion 2.1 potrebbero essere meno popolari rispetto ai modelli basati su SD 1.5 o SD 1.4. Questo perché SD 2.1 è generalmente considerato un po’ meno creativo e malleabile e potrebbe rispettare un po’ meno i prompt testuali.
Nella prossima sezione della guida, illustreremo le funzioni di base dell’interfaccia web per generare immagini con i modelli Stable Diffusion. Tuttavia, è importante tenere presente che l’argomento è vasto e in continua evoluzione, con la comunità che crea costantemente nuove estensioni per guidare la generazione delle immagini, inclusi strumenti come ControlNet Openpose per indirizzare pose specifiche delle persone.
Nella parte in alto a sinistra dell’interfaccia utente (UI), troverai un campo che indica il modello Stable Diffusion (SD) che verrà utilizzato per generare le immagini. Si tratta di una selezione da una lista che include tutti i modelli scaricati nella cartella “A1111 Web UII Autoinstaller\stable-diffusion-webui\models”. Sotto il campo del modello, ci sono le schede dei moduli che possono essere utilizzati con i modelli, compresi anche le estensioni di terze parti. Per ora, ci concentreremo sulla scheda “txt2img”, che consente di generare un’immagine a partire dalla sua descrizione testuale.
All’interno di questa scheda, troverai due campi di testo: il prompt positivo nella parte superiore e il prompt negativo nella parte inferiore. I prompt devono essere scritti esclusivamente in lingua inglese. Il prompt positivo accoglie la descrizione generale o dettagliata dell’immagine che desideri produrre, mentre il prompt negativo indica gli elementi che non desideri vengano inclusi nell’immagine. Combinando i due prompt, è possibile guidare meglio il processo di generazione dell’immagine. Si consiglia di non sottovalutare l’importanza del prompt negativo, poiché può aiutare a evitare la creazione di immagini indesiderate o deformate.
È importante notare che i campi dei due tipi di prompt hanno un limite di 75 parole. Questo numero rappresenta il numero di vettori (token) che verranno forniti al modello per la creazione dell’immagine. È possibile superare il limite di 75 parole, ma in tal caso l’interfaccia web eseguirà automaticamente una media, riducendo la “qualità” dei vettori.
È anche importante tenere presente che le virgole contano come una parola, ma servono a separare semanticamente i diversi concetti e attribuire loro un’importanza diversa.
Il prompt che viene fornito al modello SD attribuisce importanza all’ordine delle parole, dove la prima parola ha un peso maggiore rispetto all’ultima. Si consiglia di rispettare questo ordine nel prompt:
- Il soggetto (es. un uomo in un parco, un elefante nella savana, ecc.)
- Lo sfondo, se non specificato nel soggetto (es. sfondo sfocato del parco, strada della città, ecc.)
- Il tipo di media (es. foto, disegno, dipinto, ecc.)
- Lo stile artistico dell’immagine (es. surrealistico, iperrealistico, fantasy, ecc.)
- La qualità dell’immagine (es. altamente dettagliata, messa a fuoco nitida, dettagli intricati, ecc.)
- I dettagli aggiuntivi (es. incredibilmente bello, distopico, ecc.)
- I colori (es. viola, rosa, oro iridescente, ecc.)
- La luce (es. luce naturale, illuminazione a faretto, luce flash, giorno, mezzogiorno, notte, ecc.)
Nel prompt negativo, ipotizzando che si voglia creare l’immagine di una persona, si potrebbe scrivere: “qualità peggiore, bassa qualità, artefatti jpeg, watermark, firma, fuori dall’inquadratura, amatoriale, mani disegnate male, volto disegnato male, pupille deformate, mutilato, dita disegnate male, occhi disegnati male, deformità, cattiva anatomia, arti extra, arti malformati, mancanza di braccia, mancanza di gambe, braccia extra, gambe extra”.
È possibile aumentare o diminuire la forza di ogni parola utilizzando una sintassi particolare che include l’uso delle parentesi e/o dei numeri. Ad esempio, scrivendo (parco:1.3), si indica al modello che si desidera che la presenza del parco nell’immagine abbia un peso maggiore e che il parco “deve” essere presente.
Al contrario, se si scrive (parco:0.8), si sta dicendo al modello che il parco non avrà un ruolo principale nell’immagine.
In Automatic1111, è possibile semplificare queste scritture utilizzando le parentesi tonde e quadre per indicare rispettivamente l’aumento e la diminuzione della forza di una parola. Gli effetti sono moltiplicativi.
Ad esempio:
Quindi, se si scrive un prompt del tipo: “foto di un uomo caucasico di 25 anni in un parco, maglietta blu, (((inquadramento a metà busto))), sfondo sfocato, luce naturale, pelle naturale, giorno, dettagli intricati, pupille centrate”, si sta dicendo al modello che si desidera fortemente un’immagine di un uomo fotografato a metà busto, evidenziandolo con le parentesi.
Si consiglia di consultare la wiki di Automatic1111 per ulteriori consigli sui prompt.
Più in basso, troverai una casella per scegliere il tipo di “sampler” e il numero di “step” che il sampler deve eseguire per ottenere l’immagine finale.
Come già spiegato, un modello Stable Diffusion genera un’immagine casuale nello spazio latente e successivamente stimola il rumore dell’immagine che viene sottratto ad ogni step. Questo processo di riduzione del rumore è chiamato “sampling” perché genera una nuova immagine ad ogni step. Il metodo utilizzato per il campionamento è chiamato sampler.
Ci sono diversi sampler tra cui scegliere. Quelli che terminano con “a”, come “Euler a”, “DPM2 a”, “DPM++ 2S a Karras”, sono considerati “ancestrali” e sono i primi ad essere stati implementati. Nonostante siano ancora utilizzati, è consigliabile preferire quelli più recenti. Tuttavia, non esiste un sampler che sia migliore di tutti gli altri, e spesso il loro successo dipende anche dal modello specifico su cui vengono applicati.
Accanto alla scelta del sampler, è possibile specificare il numero di step da eseguire. Non è detto che un maggior numero di step porti a un risultato migliore. Un numero elevato di step richiede più calcoli e più tempo per generare l’immagine, che potrebbe diventare eccessivamente elaborata e presentare artefatti o “mostruosità” a causa di errori accumulati negli step successivi.
Un range accettabile di step si situa tra 20 e 35. Ad esempio, il sampler Euler di solito funziona meglio con un numero sostanziale di step, mentre un altro sampler molto noto, DPM++ 2M Karras, può fornire buoni risultati con un range compreso tra 20 e 29 step. La seguente griglia è un esempio di come lo stesso prompt e seed vengono interpretati con sampler e numero di step diversi.
La risoluzione dell’immagine indica il numero di pixel in altezza e larghezza dell’immagine finale. È consigliabile utilizzare dimensioni come 512 x 512 o 768 x 768, o una combinazione di questi valori, poiché i modelli funzionano meglio con queste risoluzioni.
Se si desidera aumentare la risoluzione dell’immagine, è possibile utilizzare l’opzione “Hires. Fix” sotto il metodo di campionamento. Questa opzione opererà durante la creazione dell’immagine e in alcuni modelli può migliorare i risultati. Tuttavia, è importante considerare l’utilizzo di memoria richiesto da Hires. Fix. Se si lavora con risoluzioni superiori a 512 x 512 o 768 x 768 e non si dispone di una scheda grafica con molta VRAM, potrebbe essere raggiunta la saturazione della memoria senza ottenere un’immagine finale.
Il flag “Restore faces” accanto a Hires. Fix dovrebbe essere selezionato se si desidera generare un’immagine che include un volto, poiché può migliorare l’aspetto dei volti e aiutare a evitare risultati indesiderati.
Più in basso si trova l’impostazione CFG Scale, che sta per Classifier Free Guidance e indica quanto il sistema dovrebbe essere libero nell’interpretare la descrizione testuale fornita nel prompt.
Valori più bassi consentiranno al modello di essere più creativo, mentre valori più alti costringeranno il modello a seguire con maggiore precisione le parole del prompt. Solitamente, dopo CFG 10, si possono ottenere immagini errate con evidenti difetti grafici, mentre valori troppo bassi possono generare risultati incomprensibili. Di solito, un valore ottimale per CFG Scale si situa tra 5 e 7.
Il seed è un numero che genera la prima immagine, da cui successivamente verrà sottratto il rumore attraverso gli step. Un valore di seed pari a -1 significa che il seed sarà casuale ad ogni generazione, anche se il prompt rimane lo stesso. Se si utilizza lo stesso seed per ogni generazione, le immagini finali saranno molto simili tra loro.
Una volta impostati tutti i valori desiderati, facendo clic sul grande pulsante “Generate” in alto a destra, verrà avviato il processo di generazione dell’immagine. È possibile interrompere il processo facendo clic sul pulsante “Interrupt”, che apparirà al posto del pulsante “Generate” una volta che il processo è iniziato.
In Stable Diffusion, si possono incontrare i file LoRa e le Textual Inversion. LoRa sta per “Low-Rank Adaptation” ed è un processo di fine-tuning per i modelli. Di solito, questi file non superano i 144 MB e vengono utilizzati per allenare i modelli al fine di ottenere risultati specifici, come il volto di un attore famoso, un tipo di abbigliamento o uno stile artistico. Tuttavia, i file LoRa non possono essere utilizzati da soli, ma devono sempre essere usati insieme a un modello Stable Diffusion principale. Ad esempio, si potrebbe utilizzare un file LoRa per creare delle action figure.
I file LoRa hanno estensione .safetensor e devono essere scaricati nella cartella “A1111 Web UI Autoinstaller\stable-diffusion-webui\models\Lora”. Per attivarli nella Web UI, è possibile richiamarli utilizzando un apposito pulsante che elenca tutti i file LoRa installati. Facendo clic su di essi, possono essere utilizzati per sostituire una parola nel prompt e di solito sono racchiusi tra i caratteri < >, con indicato anche il loro peso. Ad esempio, lora:sneakers_v10:1.

Le Textual Inversion, invece, sono un modo alternativo per controllare lo stile dell’immagine. Questi file sono molto più piccoli, di solito occupano pochi KB, e vengono utilizzati per allenare un modello a ricreare i volti di una persona specifica, ma non solo. Ad esempio, si potrebbe utilizzare una Textual Inversion per dare uno stile di “vecchia foto” alla descrizione testuale di una banca. I file Textual Inversion hanno estensione .pt e devono essere scaricati nella cartella “A1111 Web UI Autoinstaller\stable-diffusion-webui\embeddings”. Vengono inseriti nel prompt in modo simile ai file LoRa, racchiusi tra i caratteri < >. Spesso, hanno una o più parole chiave che li attivano e devono essere inserite nel prompt come dettagli forniti nella pagina di download della Textual Inversion.
Stable Diffusion e la Web UI offrono molte altre funzionalità. Ad esempio, è possibile spostare un’immagine appena creata nel modello “inpaint” utilizzando l’apposito pulsante. In questo modello, è possibile specificare con una maschera quale parte dell’immagine deve essere modificata. Verrà quindi generata una nuova immagine che modificherà solo l’area “dipinta” utilizzando il pennello disponibile nel modulo.
Questa tecnica può essere utile per correggere errori durante la creazione iniziale, poiché i modelli non sono ancora in grado di riprodurre con precisione le mani e le dita umane. Può essere utilizzata anche per superare i limiti delle dimensioni delle immagini create, come ad esempio quelle con risoluzioni diverse da 512 x 512 o 768 x 768 o 512 x 768. Utilizzando l’inpainting, è possibile allargare e riempire l’immagine in un aspetto più orizzontale, facendo sì che il modello crei ciò che manca. Solitamente, ci sono modelli specifici dedicati all’inpainting.
Ad esempio, si potrebbe creare un’immagine di un astronauta in una foresta con un rapporto di forma 1:1 e successivamente utilizzare l’inpainting per dare più spazio alla foresta sullo sfondo, ottenendo un aspetto più orizzontale.
In alternativa, è possibile utilizzare uno script chiamato “Poor man’s outpainting” del modulo img2img, che consente di espandere l’immagine nelle quattro direzioni (sopra, sotto, a sinistra, a destra) di una quantità di pixel definita dall’utente, generando una nuova immagine. Questa è una soluzione più semplice rispetto all’inpainting completo, ma può comunque consentire di ottenere un aspetto di forma diversa.
L’inpainting e il modulo img2img per ottenere una nuova immagine da un’immagine di partenza sono solo alcune delle numerose possibilità offerte da Stable Diffusion. Tuttavia, è importante fare una precisazione importante: non è possibile sapere quali immagini sono state utilizzate dagli utenti terzi per creare modelli personalizzati, e è probabile che ciò possa violare le leggi sul copyright in diversi Paesi. Purtroppo, non è possibile stabilirlo con certezza.



